Heroku Connection to Log Stream Failed. Please Try Again Later.
Platforms similar Heroku requite you the freedom to focus on building great applications rather than getting lost setting up and maintaining infrastructure. Ane of the many smashing features of working with it is the Heroku logs that enable monitoring your stack error troubleshooting. Information technology helps speed up the process when things go wrong.
In this Heroku tutorial, we'll uncover best practices for making the nigh of Heroku logs. Allow's brainstorm with a survey of Heroku's basic anatomy to provide a articulate understanding of the terms and mechanics of Heroku'due south logging functionality. Experience costless to skip to the logging part if you're already familiar.
Heroku Logs Crook Sheet
Hither's a summary of CLI commands that are relevant for Heroku logging for your reference.
| Command | Clarification |
heroku logs -t heroku logs -southward app heroku logs -tp router | –tail real-fourth dimension log stream –source only on app logs -tp router log entries simply |
$ heroku logs -due north 200 | num specify the number of log entries to display. |
$ heroku logs --d router | –dyno add filter to specify source, here, |
$ heroku logs --source app | –source specify which log source, in this example, APP logs. |
heroku drains --json | Obtain tokens for add-on log apps |
heroku releases | List all releases Info on a version Rollback a release |
heroku addons:add together heroku-coralogix | Add a log analytics add-on |
Heroku Basic Architecture
Applications deployed on Heroku live in lightweight Linux containers called Dynos. Dynos can range from holding simple spider web apps to complex enterprise systems. The scalability of these containers, both vertically and horizontally, is ane of the flexible aspects of Heroku that developers leverage. They include the following types:
- Web Dynos are web processes that receive HTTP traffic from routers. (We will demonstrate a Spider web Dyno in the "Hands On" Python app sample nosotros create afterwards in this resource.)
- Worker Dynos may be whatsoever non-web-type process type that is used for groundwork processes, queueing, and cron jobs.
- One-off dynos are ad-hoc or temporary dynos which can run every bit either attached or detached from local machines. One-off Dynos are typically used for DB migrations, console sessions, groundwork jobs, and diverse other administrative tasks, such every bit processes started by the Heroku Scheduler.
Heroku Logging Nuts
Nearly PaaS systems provide some grade of logging. Nevertheless, Heroku provides some unique features which fix information technology apart. One such unique feature is the Logplex tool which collects, routes, and collates all log streams from all running processes into a single aqueduct that can exist directly observed. Logs can exist sent through a Bleed to a tertiary-party logging add together-on which specializes in log analytics.
For developers, i of the most important tools in Heroku is the control-line interface (CLI). Afterwards Heroku is installed locally, developers utilize the CLI to do everything including defining Heroku logs, filters, targets, and querying logs. We will explore the Heroku logging CLI in particular throughout this resource.
Heroku View Logs
The most usually used CLI command to remember logs is:
$ heroku logs
Allow's wait at the beefcake of an Heroku log. Kickoff, enter the post-obit CLI command to brandish 200 logs:
$ heroku logs -n 200
Heroku would evidence 100 lines past default without the -northward parameter above. Using the -n, or –num parameter, nosotros tin display up to 1500 lines from the log. Here is an example of a typical log entry:
2020-01-02T15:13:02.723498+00:01 heroku[router]: at=info method=GET path="/posts" host=myapp.herokuapp.com" fwd="178.68.87.34" dyno=spider web.i connect=1ms service=18ms status=200 bytes=975
2010-09-16T15:thirteen:47.893472+00:00 app[worker.three]: two jobs processed at 16.6761 j/due south, 0 failed ...
In the in a higher place entry, we tin see the following information:
- Timestamp – The precise time when the Dyno generated the log entry, according to the standard RFC5424 format. The Default timezone is UTC (see below for how to alter the default timezone).
- Source – web dynos, background workers, and crons generate log entries shown every bit app. HTTP routers and dyno managers are shown as
heroku. - Dyno – In this example,
worker #threeis the Dyno, and the Heroku HTTP router is shown asrouter. - Message – contains the content, in this case, the
statuswhich is equal to 200, and the byte length. In practice, the message contents typically require smart analytics apps to assist with estimation
View Heroku Logs for a Specific Dyno
The filter is some other important CLI parameter. For example, by using the post-obit filter nosotros can choose to display only the log entries originating from a specific Dyno:
$ heroku logs --dyno
View Heroku App Logs
$ heroku logs --source app
View Heroku API Logs
$ heroku logs --source app --dyno API
View Heroku System Logs
$ heroku logs --source heroku
Heroku Log Timezone
Heroku uses the UTC timezone for its logs by default. You tin can change it, although the recommended approach is to convert to the client's local timezone when displaying the data, for example with a library similar Luxon.
To check the current timezone:
$ heroku config:become TZ
To alter the timezone for Heroku logs:
$ heroku config:add TZ="America/New_York"
Here'south a total list of supported timezone formats
Log Severity Levels
To help monitor and troubleshoot errors with Heroku faster, let'south get familiar with Heroku log levels.
Log data tin be quantified by level of urgency. Here is the standard set of levels used in Heroku logs with examples of events for which Heroku Logplex generates a log entry:
| Severity | Description | Example |
| emergency | system is unusable | "Child cannot open lock file. Exiting" |
| alert | Immediate action required | "getpwuid: couldn't decide user proper name from uid" |
| critical | Threats to app functionality | "socket: Failed to get a socket, exiting child" |
| fault | Client non receiving acceptable service | "Premature finish of script headers" |
| warning | issues which don't threaten app functioning only may demand ascertainment | "child process 01 did non exit, sending another SIGHUP" |
| notice | Normal events which may need monitoring | "httpd: defenseless SIGBUS, attempting to dump core in …" |
| info | Informational | "Server is busy…" |
| debug | Logs normal events for debugging | "opening config file …" |
| trace one-8 | For finding functions in code, locating code chunks | "proxy: FTP: … " |
Types of Heroku Logs
The Heroku platform maintains four categories of logs. For instance, log entries generated by a dependency-related fault thrown when running an app are separated from messages virtually the deployment of new lawmaking. Here are summaries of the four Heroku log categories:
- App logs – Entries generated when an app runs and throws an exception, for example, for a missing dependency such as an inaccessible library.
The CLI log filter is--source app. - API logs – Developer administrative actions (such as deploying new lawmaking) trigger entries to the API log. Scaling processes and toggling maintenance mode are other examples in this category. These logs tin can exist used to set progressive delays in retrying an API call when ane fails. API logs can also be used to catch authentication failures, and problems with push requests.
The CLI filter is--source app --dyno api - Organisation logs – Contain information well-nigh hardware system and system processes, or in other words, infrastructure. When the Heroku platform restarts an app because of an infrastructure issue, (e.g. failed HTTP request), a system log entry volition be generated. The CLI filter to query system log entries is
--source heroku - Add-on logs – Improver logs are generated past add-ons to the Heroku platform, like Redis Cloud, MongoDB, SendGrid, MemCachier, etc generate their own logs.
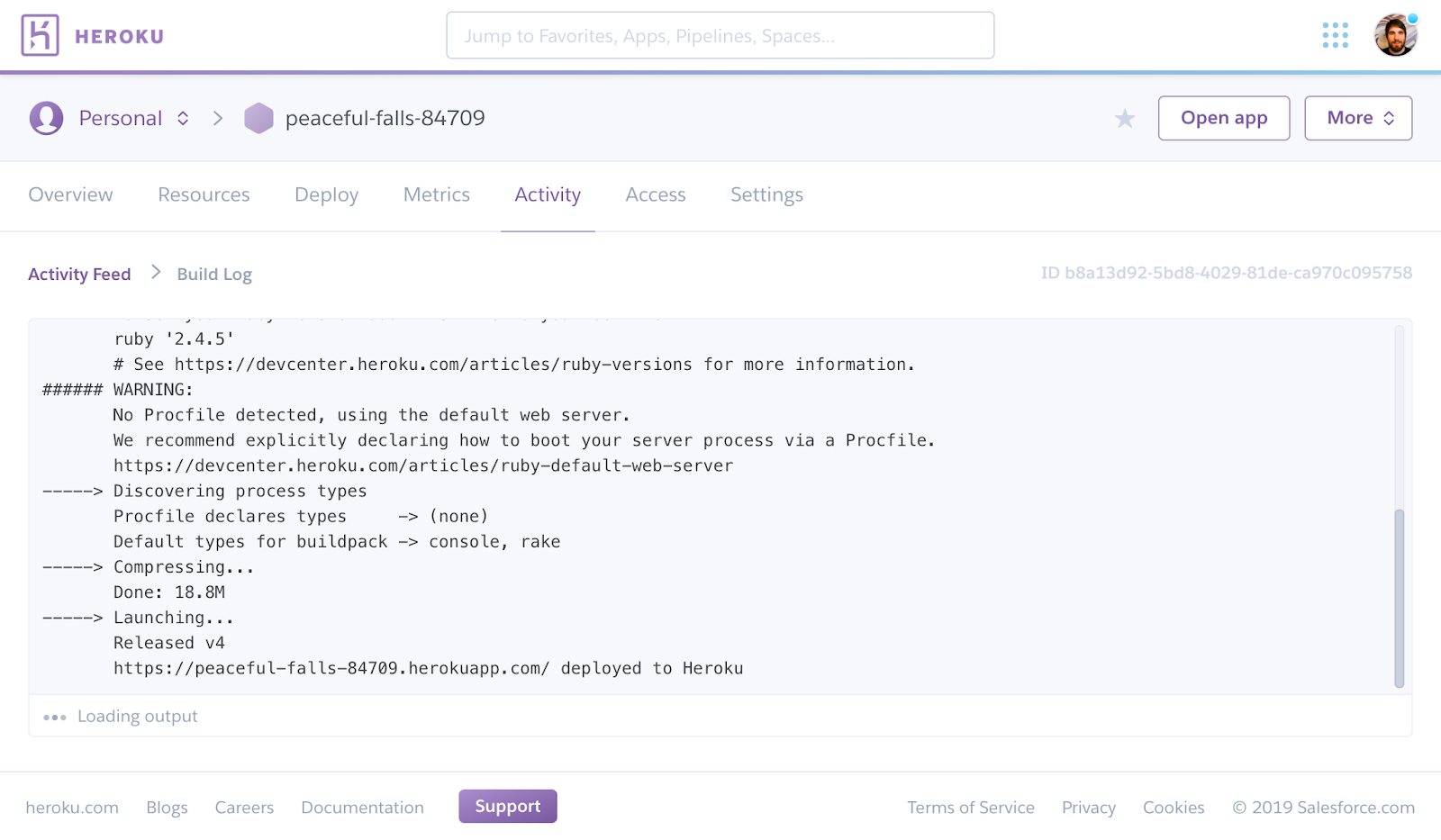
Heroku Build Logs
Heroku build logs are a special log blazon contained in the file build.logs, and generated by both successful and failed builds. These logs are accessed in your app'south activity feed on the Heroku dashboard, or the build logs can be configured with a tool like Coralogix to criterion errors for each build version. On the dashboard, click "View build log" to see build-related events in the action feed.
A running app tin can also write an entry directly to a log. Each coding language will take its own method for writing to Heroku logs. For case, see the Heroku Log Tips and Traps for Ruby-red further forth in this article. Log entries do not live forever, and as we will meet afterwards on, the fourth dimension retention of log entries is determined by log type. This attribute of logging is all-time managed through the use of a log analytics app which is machine learning (ML-capable).
Heroku Release Logs
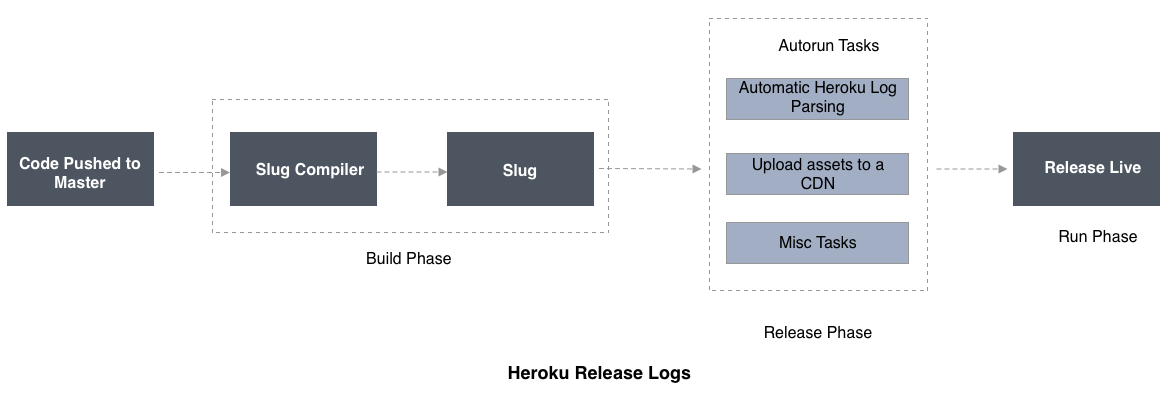
Release logs prove the status of each release of an app. This includes failed releases that are pending because of a release command which has not returned a condition yet. In the following release log entry, version 45 of an app deployment failed:
v45 Deploy ada5527 release command failed
Apply "curl" to programmatically cheque the condition of a release. Roll the Platform API for specific releases or to list all releases. Release output tin as well be retrieved programmatically by making a GET request on the URL. The output is available nether the output_stream_url attribute.
Heroku Router Logs
Router logs contain entries about HTTP routing in Heroku's Common Runtime. These correspond the entry and exit points for spider web apps and services running in Heroku Dynos. The runtime manages dynos in a multi-tenant network. Dynos in this network receives connections from the routing layer only.
A typical Heroku router log entry looks like this:
2020-08-19T05:24:01.621068+00:00 heroku[router]: at=info method=Go path="/db" host=quiescent-seacaves-75347.herokuapp.com request_id=777528e0-621c-4b6e-8eef-74caa34c1713 fwd="104.163.156.140" dyno=web.1 connect=0ms service=19ms status=301 bytes=786 protocol=https
In the example higher up, following the timestamp, we see a message beginning with 1 of the post-obit log levels: at=info, at=warning, or at=error. After the warning level the entry contains boosted fields from the following tabular array which depict the result existence logged:
| Field | Clarification |
| Heroku mistake "code" (Optional) | Error codes which supplement HTTP status codes |
| Error "desc" (Optional) | Clarification of the fault corresponding to the codes higher up |
| HTTP request "method" e.g. Go or POST | A diversity of issues |
| HTTP request "path" | URL originating the request |
| HTTP request "host" | Host header value |
| Heroku HTTP Request ID | Correlates router logs to app logs |
| HTTP request "fwd" | X-Forwarded-For header value |
| Which "dyno" serviced the request | Troubleshooting specific containers |
| "Connect" time (ms) | Establishing a connexion to the webserver |
| "Service" fourth dimension (ms) | Proxying data between the client and the webserver |
| HTTP response code or "status" | Issues discovery |
| Byte count | Size in bytes, current request |
Events which trigger log entries
Ideally, an Heroku log should contain an entry for every useful event in the beliefs of an awarding. When an app is deployed and while information technology is running in production, there are the many types of events which trigger log entries:
- Authentication , Authorization, and Access: These events include things such every bit successful and failed authentication and authorizations, organisation access, information access, and application access.
- Changes: These events include changes to systems or applications, changes to data (creation and destruction), application installation, and changes.
- Availability: Availability events include startup and shutdown of systems and applications, builds and releases, faults and errors that impact application availability, and backup successes and failures.
- Resource: Resource issues to log include wearied resources, exceeded capacities, and connectivity bug.
- Threats: Some common threats to logs include invalid inputs and security problems known to affect the application.
Log Retention Flow
The retention menses length we ready is important considering log information can speedily get out of control. Retaining unnecessary log data tin can add overhead to assay, however, discarding log data too early may reduce the opportunity for insights. One useful manner of determining which logs should exist kept and for how long tin can be defined past ensuring nosotros accept accurately established the correct Heroku log levels, and past establishing different retentivity periods based on specific criteria like the log level, system, and subsystem. This can be accomplished programmatically by yourself or with a 3rd-party tool like the Coralogix usage optimizer.
Managing Sensitive Log Data
Investigation of recent security breaches at giant eCommerce enterprises like Uber and Aeroflot surprisingly revealed that the source of the web app's vulnerability lay inpoorly configured and inadequately monitored log streams.
Many contempo cases involving customer credit card loss and proprietary source code exposure occurred considering developers were unaware that their log streams contained OAuth credentials, API surreptitious keys, hallmark tokens, and a multifariousness of other confidential information. Cloud platforms generate logs with default output containing authentication credentials, and log files may non be adequately secured. In many recent security breaches, unauthorized users gained access by way of reading log entries which contained authentication credentials.
Obscuring sensitive data should be done prior to aircraft logs, but some tools like the Coralogix parser are capable of removing specific data from logs after the logs have been shipped.
Log Runtime Metric Logs
To monitor load and retention usage for apps running in Dynos, Heroku Labs offers a feature called "log-runtime-metrics." The CLI command $ heroku logs --tail tin be used to view statistics about memory and swap use, as well equally load averages, all of which flow into the app'due south log stream.
Example runtime metric logs:
source=web.1 dyno=heroku.2808254.d97d0ea7-cf3d-411b-b453-d2943a50b456 sample#memory_total=21.00MB sample#memory_rss=21.22MB sample#memory_cache=0.00MB sample#memory_swap=0.00MB sample#memory_pgpgin=348836pages sample#memory_pgpgout=343403pages
Learn more about how to utilize runtime metrics in the documentation hither.
Heroku Log Drains: Centralizing Log Data
In order to understand Drains in Heroku logs, nosotros volition first demand to clarify how Heroku Logplex works. Logplex aggregates log information from all sources in Heroku (including dynos, routers, and runtimes) and routes the log information to predefined endpoints. Logplex receives Syslog letters from TCP and HTTPS streams from a node in a cluster, subsequently which log entries are sent to Redis buffers (the near recent 1,500 log entries are retained by default). For example, Heroku then distributes the logs to display with $ heroku logs --tail, or for our purposes, to forward the logs to Drains.
A Heroku Bleed is a buffer on each Logplex node. A Drain collects log information from a Logplex node and then forrad it to user-divers endpoints. For our purposes, Heroku Drains connect to 3rd party log analytics apps for intelligent monitoring of log data.
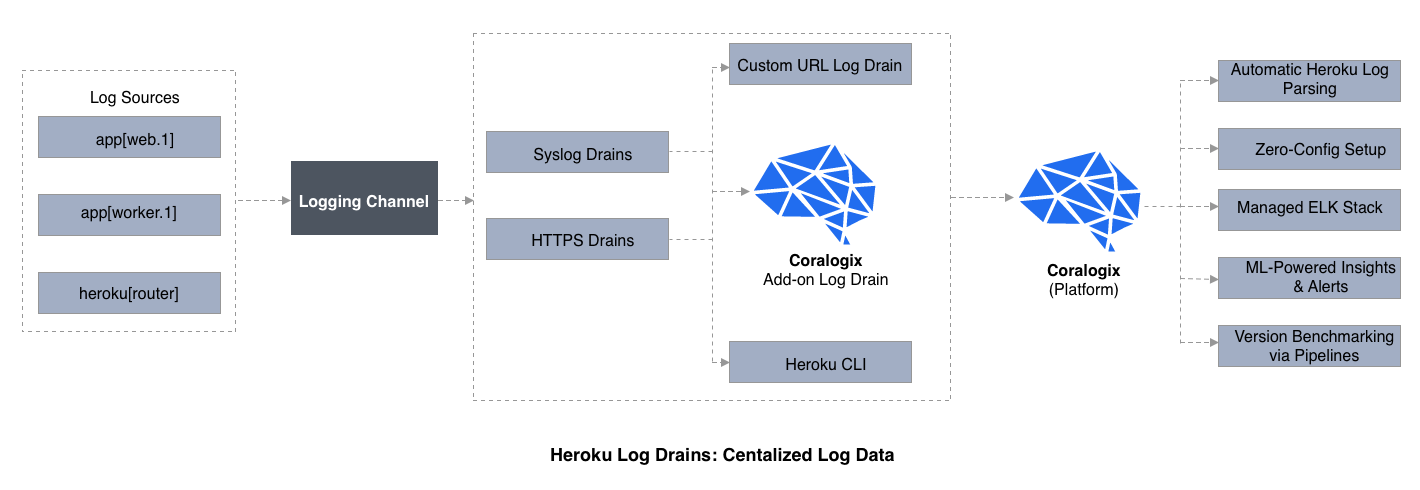
Ii Types of Heroku Log Drains
The two types of Heroku Drains provide log output to dissimilar endpoints. The two Drain types include:
- Syslog Drains – forward Heroku logs to an external Syslog server
- HTTPS Drains – write original log-processing code to frontward to a web service
How to set an Heroku Log Drain
Logplex facilitates collecting logs from apps for forwarding to log archives, to search and query, and likewise to log analytics add-on apps. To manage how application logs are candy, nosotros can add Drains of the two types mentioned earlier: Syslog drains, and HTTPS drains.
1 – Install a log analytics app, preferably one with machine learning analytics adequacy, and obtain the potency token to admission that app.
2 – Configure a Syslog or HTTPS Heroku Log Drain to send information from an app running in a Heroku Dyno to the Add-on analytics app (appName).
Here is the CLI control to get-go a TLS Syslog bleed:
$ heroku drains:add syslog+tls://logs.this-example.com:012 -a appName
And for the same appName, here is the manifestly text Syslog drain:
$ heroku drains:add together syslog://logs.this-example.com -a appName
To configure an HTTPS drain, use:
$ heroku drains:add together https://user:[email protected]/logs -a appName
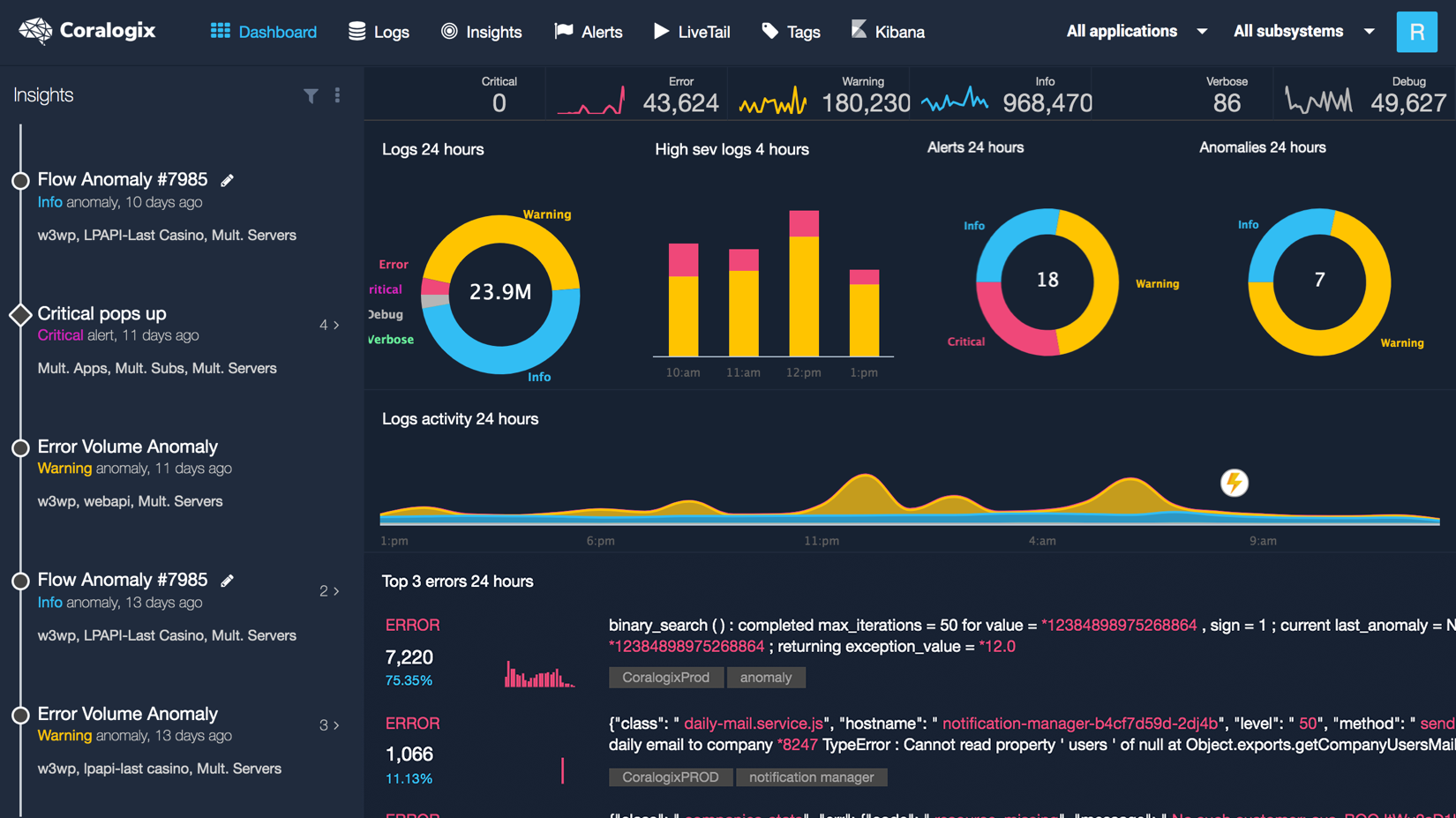
3 – Monitor the performance of the app running in the Dyno with the dashboard of visualizations provided by the add-on analytics app. Here is what it looks like while monitoring the live tail of an app with Coralogix Add-on:
Heroku Tail Logs
The Heroku logs –tail option is the real-time tail parameter. Its purpose is to display current log entries while keeping the session live for additional entries to stream while the app continues to run in product. This is useful for testing alive apps in their working environments. In that location are several subtle points to real-fourth dimension log monitoring. Permit's look at some of the fundamentals earlier we tackle the bodily usage of the log –tail.
Heroku handles logs equally fourth dimension-ordered event streams. If an app is spread across more one Dyno, then the full log is non contained in *.log files, because each log file simply contains a view per container. Because of this, all log files must be aggregated to create a complete log for analysis.
Moreover, Heroku's filesystem is temporary. Whenever a Dyno restarts all prior logs are lost. Running Heroku console or "run bash" on Cedar Stack does not connect a running Dyno, but instead creates a new one for this bash command, which is why this is called a "one-off process." So, the log files from other Dynos don't include the HTTP processes for this newly created Dyno.
With this in mind, to view a existent-time stream from a running app for example, use the -t (tail) parameter:
$ heroku logs -t
2020-06-16T15:thirteen:46-07:00 app[web.ane]: Processing PostController1#listing (for 208.39.138.12 at 2010-09-16 xv:13:46) [GET] 2020-09-16T15:13:twenty-07:00 app[web.1]: Rendering template layouts/application 2020-06-16T15:thirteen:46-07:00 heroku[router]: Become myapp.heroku.com/posts queue=0 wait=1ms service=2ms bytes=1975 2020-06-16T15:xiii:47-07:00 app[worker.12]: 23 jobs processed at 16.6761 j/s, 0 failed ...
In the above log entry, we are observing the behavior or a running app. This is useful for live monitoring. To store the logs for longer periods, and for triggers, alerts, and assay, we tin create a drain to an add-on log analytics app like Coralogix.
Heroku logging with specific languages
Each language has its own built-in logging functionality which tin can write to Heroku logs. Third-party logging apps are specifically designed to extend born logging functions and to recoup for inadequacies.
Ruby was the original language supported by Heroku. As a result, many of the well-known developer shortcuts for making best use of Heroku logs arose from developing and deploying Cerise apps. For instance, it'due south possible for a running app to write entries to logs. In Ruby, this is washed with puts:
puts "User clicked twice before callback consequence, logs!"
The same log entry would be written with Coffee like this:
System.out.println("User clicked twice before callback outcome"); In the following sections, we'll explore tips for working with popular programming languages and Heroku.
Heroku Logging with Cherry
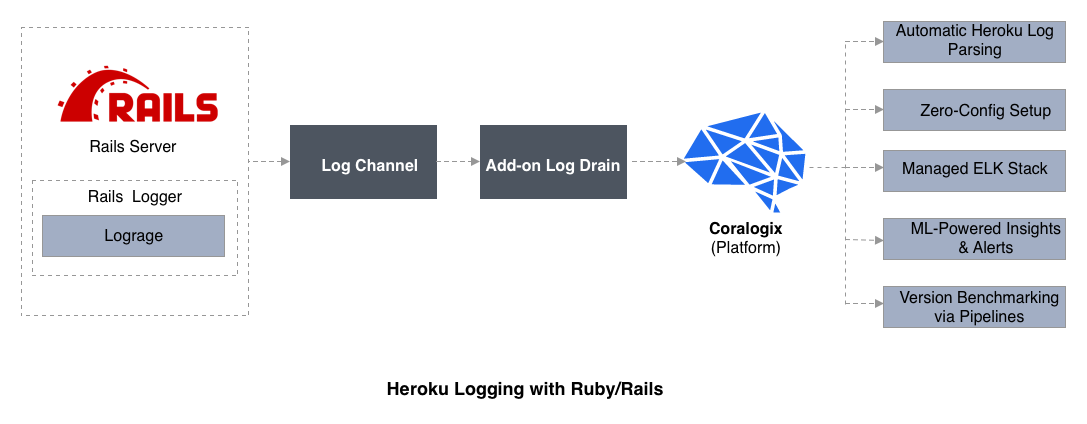
Crimson / Rail was the first coding linguistic communication supported past Heroku, and Rails works without trouble. All the same there are measures which further optimize Rails app logging with Heroku. Here are several tips which may not be obvious to developers who are but starting time to deploy Rails to Heroku.
- Configure a Track apps to connect to Postgres
- Configure logs to stream to STDOUT.
- Enable serving avails for the app in production.
Writing to STDOUT
Heroku logs are data streams which flow to STDOUT in Rails. To enable STDOUT logging, add together the rails_12factor gem. This measure will configure the awarding to serve assets while in production. Add this to the Gemfile:
precious stone 'rails_12factor', grouping: :product
In order to write logs from lawmaking, equally mentioned earlier, use the following command:
puts "User clicked twice before callback result, logs!"
This will send the log entry to STDOUT. Omission of this configuration footstep volition result in a alert when deploying the app, and avails and logs will not function.
Crimson Logging Libraries
- Lograge for Runway offers sophisticated log interpreting functions for Rails including request and URL endpoints for Go, Postal service, or PUT.
- Request status: the HTTP condition codes generated for a completed asking and their elapsed response time.
- Controller and action: a function to send a request from the application router
- Templates and partials: generate log entries nigh files required to create web page views for a URL endpoint
Heroku Logging with Node.js
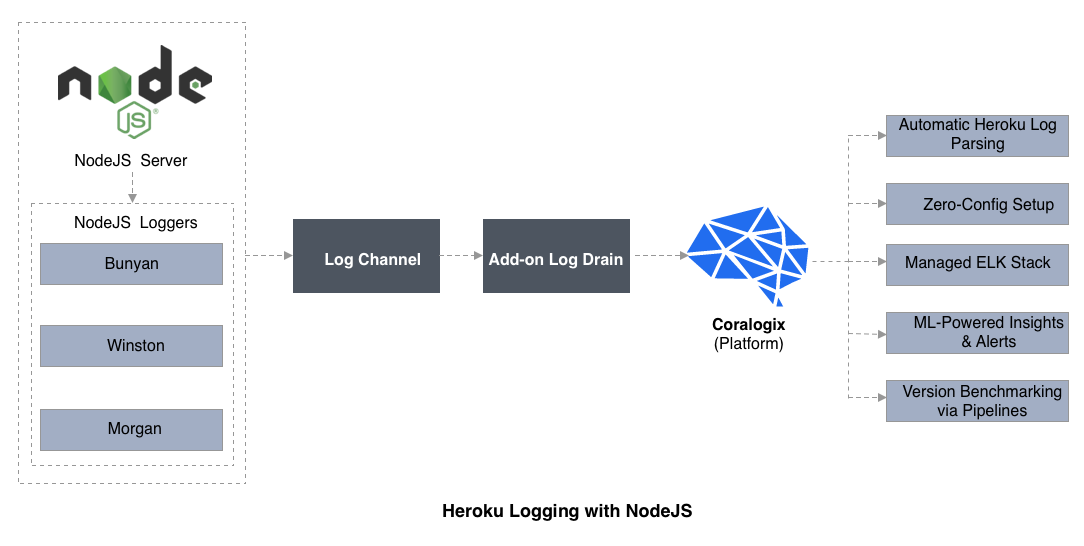
Important log attributes to define before testing a Node.js service on Heroku include:
- Event timestamps
- Log format readable to human and auto
- Log path to standard output files
- Log priority levels to dynamically select log output
The following are mutual issues and tips for logging with Heroku and Node.js.
Mismatched Node Versions
A commonly overlooked fault when deploying Node.js on Heroku tin occur from mismatched Node versions. This consequence will announced in the Heroku build log. The Node.js version in the production surroundings should match that of the evolution environment. Hither is the Heroku CLI command to verify local versions:
$ node --version
$ npm --version
We tin can compare the results with parcel.json engines version by looking at the Heroku Build Log, which volition look like this:

If the versions don't match, be sure to specify the correct version in packet.json. In this manner you tin can use Heroku Logs to identify build problems when deploying Node.js apps.
Async
Async and callbacks are primal to the functionality of Node.js apps. When deploying circuitous apps, we need tools that get across console.log. 1 obscure detail is that when the Heroku log destination is a local device or file, the panel acts synchronously. This prevents messages from getting lost when an app terminates unexpectedly. However, the console acts asynchronously when the log aqueduct is a pipe. This prevents a problem when a callback results in long period blocking.
Node.js Logging Libraries
Many developers will naturally gravitate toward an async logging library like Winston, Morgan, or Bunyan. The quintessential feature of Winston is its support for multiple transports which can be configured at various logging levels. However, problems with Winston include a lack of important details in its default log formatting. An instance of missing details is log entry timestamps. Timestamps must be added via config. The lack of machine names and procedure IDs make information technology difficult to apply the adjacent layer of 3rd party smart log analytics apps. However, Heroku Add-Ons like Coralogix can easily work with Winston and Bunyan.
Heroku Logging with Python
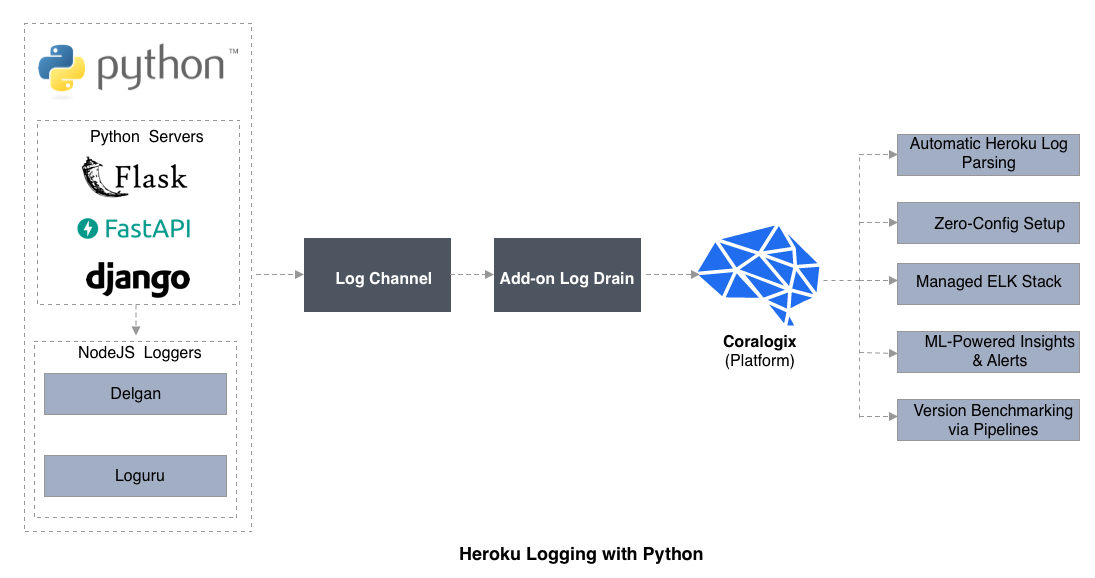
When deploying a Python spider web app, testing and debugging can exist frustrating if log entries are difficult to interpret. Using print() and sys.stdout.write() may not generate meaningful log entries when deploying to the Cloud and using the CLI command $ heroku logs to display log entries. Moreover, it is challenging to debug Python runtime errors and exceptions, considering the origin of the HTTP request mistake may not be apparent. Then, how can we write log entries from Python to resolve this issue?
The underlying source of this general problem is that while stdout is buffered, stderr is not buffered. One solution is to add sys.stdout.flush() post-obit print statements. Another tip to ensure the HTTP mistake origin is captured in the log is to verify that the right IP/PORT is monitored. If so, HTTP access entries from GET and index.html should appear in the Heroku log.
Configuring a web framework to run in debug mode will make log entries verbose. Stacktraces should display in the browser's developer console. The setting in Flask to attain this effect is:
app.config['DEBUG'] = True or app.run( ….. , debug=Truthful)
Finally, when configuring a procfile to initiate the python CLI, apply the '-u' option to avert stdout buffering in the following manner:
python -u script.py
If using Django, utilize:
import sys impress ("hello complicated world!") sys.stdout.flush() As mentioned earlier, the Python logging library itself is the standard for Python coding, as opposed to other third party offerings. The Python developer community provides limitless blogs on trips and traps of Python logging with Heroku.
Logging Libraries for Python
The congenital-in Python logging functionality is the standard, while tertiary party offerings from Delgan and Loguru are really intended to simplify the utilise of built-in Python logging.
Here is a logging instance with Python using loguru library. Loguru uses the global "anonymous" logger object. Import loguru as shown in the code sample beneath. So,
use demark() with a proper noun to identify log entries originating from a specific logger in this way:
from loguru import logger def sink(message): record = message.record if record.get("proper name") == "your_specific_logger": impress("Log comes from your specific logger") logger = logger.bind(name="your_specific_logger") logger.info("An entry to write out to the log.") Heroku Logging with Golang

Go'due south congenital-in logging library is called "log," and it writes to stderr by default. For simple error logging, this is the easiest option. Here's a division by zero fault entry from the built-in "log":
2020/03/28 xi:48:00 can't split past zero
Each programming language supported by Heroku contains nuances, and Golang is no exception. When logging with Golang, in society to avoid a major pitfall while sending log output from a Golang application to Heroku runtime logs, nosotros must be clear virtually the difference between fmt.Errorf and fmt.Printf.
Writing to standard out stdout and standard fault stderr in Go sends an entry to the log, only fmt.Errorf returns an error instead of writing to standard out, whereas fmt.Printf writes to standard out. Be aware too that Go's congenital-in log bundle functions write to stdout by default, but that Golang'due south log functions add info such as filenames and timestamps.
Logging Libraries for Golang
The built-in Golang logging library is called "log." It includes a default logger that writes to standard fault. By default, it adds the timestamp. The congenital-in logger may suffice for quick debugging when rich logs are non required. The "Hello world" of logging is a partitioning by zero error, and this is the realm of Golang'south congenital-in logger. For more sophisticated logging there are:
logrus is a library that writes log entries as JSON automatically and inserts typical fields, plus custom fields divers by configuration. Encounter more at Logrus.
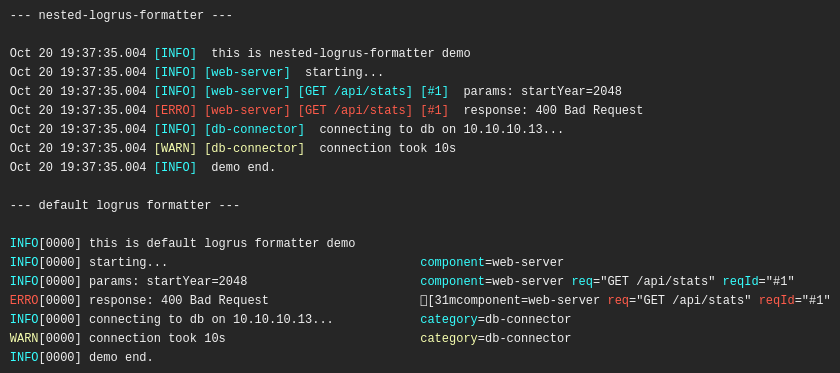
glog is especially designed for managing high volume logs with flags for limiting volume to configured problems and events. Come across more at glog.
To explore Golang tracing, OpenTracing is a library for building a monitoring platform to perform distributed tracing for Golang applications.
Heroku Logging with Java
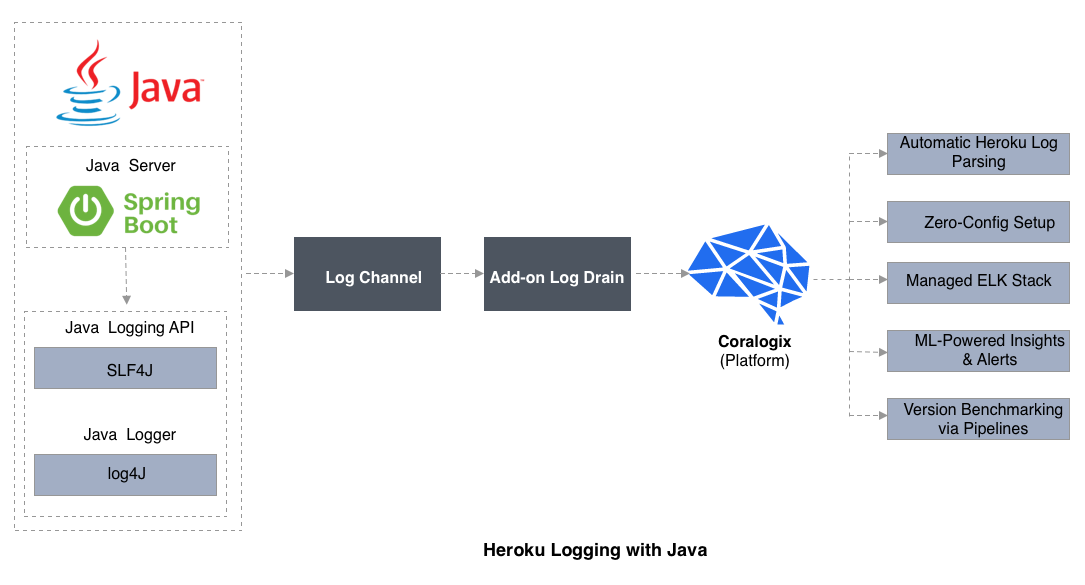
Allow'due south await at an example app using a Balance API with JAX-RS. The purpose of this instance is to demonstrate how to write log entries that place which client request generated the log entry. We reach this by using MDCFilter.coffee and import MDC with:
import org.slf4j.MDC;
And hither is an case use:
@Diagnostic public class MDCFilter implements ContainerRequestFilter, ContainerResponseFilter { private static zfinal String CLIENT_ID = "client-id"; @Context protected HttpServletRequest r; @Override public void filter(ContainerRequestContext req) throws IOException { Optional clientId = Optional.fromNullable(r.getHeader("Ten-Forwarded-For")); MDC.put(CLIENT_ID, clientId.or(defaultClientId())); } @Override public void filter(ContainerRequestContext req, ContainerResponseContext resp) throws IOException { MDC.remove(CLIENT_ID); } private String defaultClientId() { return "Direct:" + r.getRemoteAddr(); } } Every bit we volition hash out log4J in our section on Java logging libraries, here is a conversion blueprint:
log4j.appender.stdout.layout.ConversionPattern= %d{yyyy-dd-mm HH:mm:ss} %-5p %c{1}:%L - %Ten{customer-id001} %g%n Java Logging Libraries
SLF4J is not actually a library for Coffee logging, simply instead implements other Coffee logging libraries at deployment fourth dimension. The "F" in the name is for "Facade," the implication being that SLF4J makes it piece of cake to import a library of pick at deployment time. Log4J is 1 such Java logging library. Below are some interesting capabilities of log4J.
- Ready logging behavior at runtime
- Alter log format by extending the class Layout
- Thread-condom log implementation
- Appender interface exposes target of log output
- Capability to import and use other logging facilities
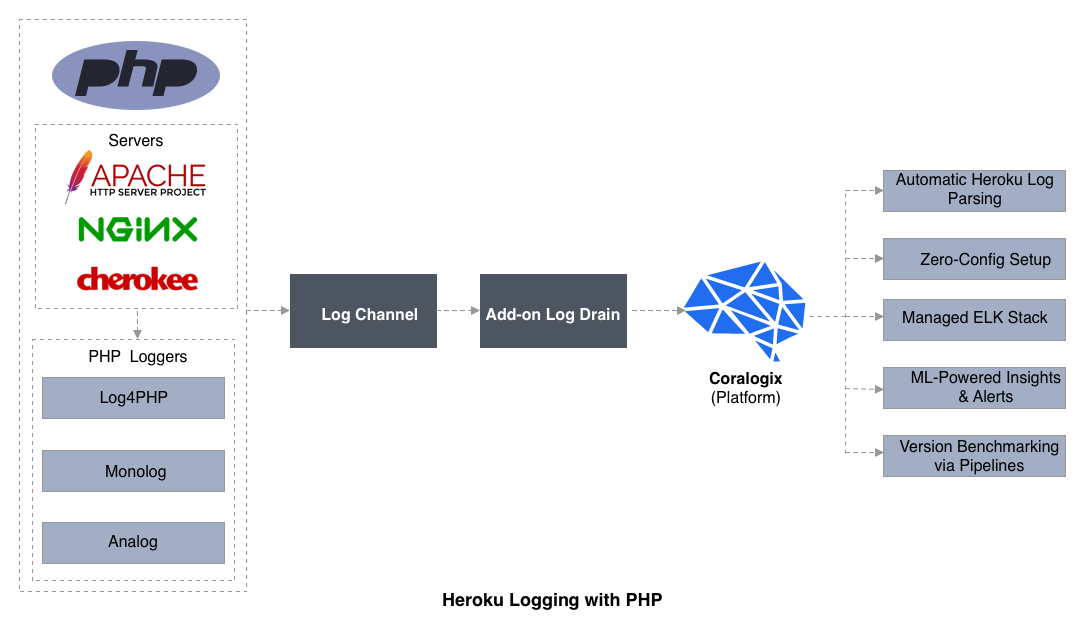
Heroku Logging with PHP
PHP writes and routes log entries in a diversity of ways which depend on the configuration of err_log in the php.ini file. To write log output to a file, name the file in err_log. To send the log output to Syslog, simply set err_log to Syslog, so that log output will become to Os logger. In Linux, the newer Rsylog uses the Syslog protocol, while on Windows information technology is the Effect Log. The default behavior, in the event that err_log is not set, is the creation of logs with the Server API (SAPI). The SAPI will depend on which PaaS is implemented. For example, a LAMP platform will use the Apache SAPI and log output will stream to Apache mistake logs. This example php.ini will include the maximum log output to file:
; Log all errors Error_reporting = E_ALL ; Don't display any errors in the browser display_errors = 0ff ; Write all logs to this file: error_log = my_file.log
Logging Libraries for PHP
Although the popular frameworks for PHP like Laravel and Symfony have logging solutions built-in, there are several logging libraries that are noteworthy. Each has a ready of advantages and disadvantages. Let'due south take a look at the of import ones:
- Log4PHP is an Apache Foundation library for PHP logging. It features functionality including logging to multiple destinations and log formatting. With the configuration file multiple handlers can be set up. These are called "appenders." The only disadvantage is that Log4PHP isn't PSR-3 compliant. Another disadvantage is that it does non support namespacing for classes, so it's hard to integrate into large apps.
- Monolog is a PSR-three compliant logging library for PHP. With integration components for most pop frameworks including Symfony and Laravel, Monolog is the nearly comprehensive logging solution for PHP. Monolog supports logging to target handlers for browser console, database, and messaging apps like Slack. And Monolog too integrates with log analytics apps like Coralogix and Loggly.
- Analog library is a simplistic logging solution compared to Monolog and does not have features similar log formatters. Log handlers for electronic mail, database, and files are configured via static access to the Analog class of objects.
Heroku Logging with Scala
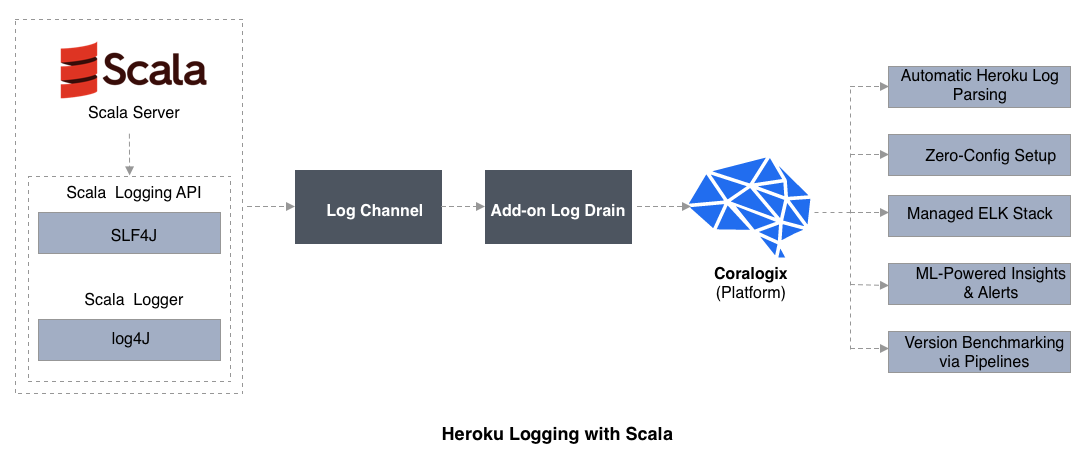
Scala-logging is essentially SLF4J for Java, merely wrapped for use with Scala. In fact, SLF4J will run on a variety of logging frameworks including log4j which adds SLF4J to our application dependencies.
1) The first step to use SLF4J with Scala is to add the dependency for logging: Open up build.sbt in an editor. Add scala-logging past including this:
proper noun := "Scala-Logging-101" version := "0.1" scalaVersion := "2.12.7" libraryDependencies += "com.typesafe.scala-logging" %% "scala-logging" % "3.9.0"
2) Now, download the jar files for logback and include this in the runtime classpath.
3) Side by side, create a new directory in the project folder and call it "libs." Add libs to the project classpath.
4) Select "Open Module Settings" with a right-click on the projection proper noun. At present, select the "Dependencies" tab and add a new directory.
v) Select "Add jars" or directories and so Idea volition open up the chooser to select the indicated folder.
6) Download logback jars and open the archive.
7) Copy logback-archetype-(version).jar and logback-core-(version).jar to the libs directory.
8) Now we can run code and direct the output to an Heroku Drain.
import com.typesafe.scalalogging.Logger object Scala-Logging-101 extends App { val logger = Logger("Root") logger.info("Hi Scala Logger!") logger.debug("Hello Scala Logger!") logger.error("Hello Scala Logger!") } The output will flow through the Heroku Bleed already created and look similar this:
18:14:29.724 [primary] INFO ROOT - Hello Scala Logger! eighteen:fourteen:29.729 [main] DEBUG ROOT - Hi Scala Logger! 18:fourteen:29.729 [primary] ERROR ROOT - Howdy Scala Logger!
Heroku Logging with Clojure
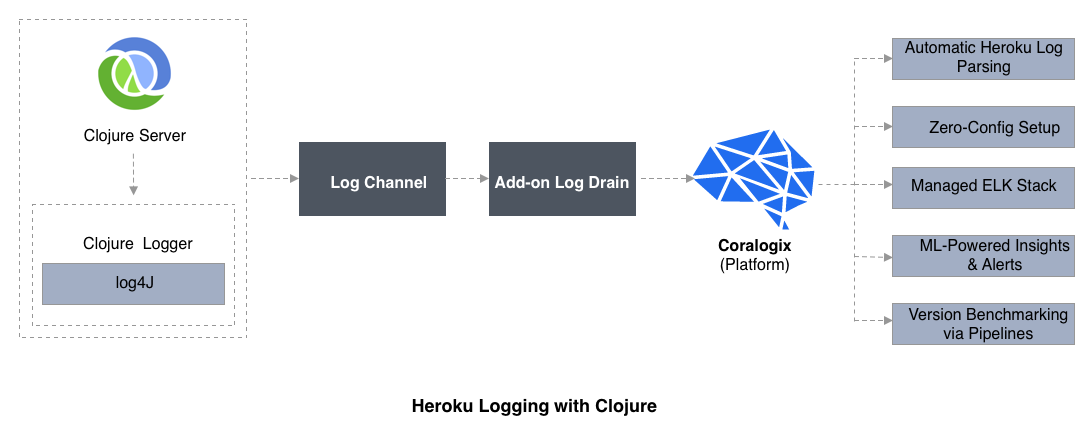
Typically, Clojure developers utilize Log4j when deploying apps with Heroku. As we volition see in the adjacent section on logging libraries for specific coding languages, Log4j was developed for Java, but is at present used for several other languages too.
The beginning pace is to set <code>clojure.tools.logging</code> and Log4j to write to Heroku logs. The <code>clojure.tools.logging</code> volition write to standard output such as Heroku-style 12 Factor App and Syslog, and likewise as structured log files which volition ultimately be translated by log analytics apps to provide alerts and operation monitoring.
To starting time writing to logs from Clojure, starting time, add <code>clojure.tools.logging</code> and <code>log4j</code> to dependencies in <code>project.clj</lawmaking> using the following:
:dependencies [[org.clojure/tools.logging "1.one.0"] [log4j/log4j "2.0.8" :exclusions [javax.mail/postal service javax.jms/jms com.dominicus.jmdk/jmxtools com.sun.jmx/jmxri]] ;; ...code hither ]
Next set up the properties file for Log4j in resource/log4j.properties like this:
log4j.rootLogger= mistake, stdout log4j.appender.stdout=org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target=Arrangement.out log4j.appender.stdout.layout=org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern=%p @ %l > %one thousand%n
To examination this implementation, we will run a code snippet that contains errors which will then generate anticipated log entries. Salvage the following code to the file src/myApp/cadre.clj. Create a file named "myApp" containing the following code snippet:
(ns myApp.core (:require [clojure.tools.logging :equally log])) ;; Write log statements at severity levels: (log/trace "Lowest log level") (log/debug "Coder info") (log/warn "Warning") ;; Various log entries: (log/info "Operation effect happened:" {:name1 12 :name2 :que} "fourth dimension out.") ;; Exceptions: (endeavor (/ 10 (dec i)) ;; <-- division by zero. (catch Exception e (log/error e "Segmentation by nothing."))) This volition produce log entries like the following:
2020-02-20 13:eighteen:38.933 | ERROR | nREPL-worker-two | myApp.cadre | Division by aught
To remain consistent with best practices in CI/CD we should consider automating log analytics. The next natural step in deploying Clojure is to use Log4j appenders to send logs to an app such as Coralogix to provide alerts, charting, and other visualizations. For instance:
log4j.appender.CORALOGIX=com.coralogix.sdk.appenders.CoralogixLog4j1Appender log4j.appender.CORALOGIX.companyId=*insert your company ID* log4j.appender.CORALOGIX.privateKey=*Insert your company private key* log4j.appender.CORALOGIX.applicationName=*Insert desired Awarding name* log4j.appender.CORALOGIX.subsystemName=*Insert desired Subsystem name* log4j.rootLogger=DEBUG, CORALOGIX, YOUR_LOGGER, YOUR_LOGGER2, YOUR_LOGGER3
Heroku Logging with C#
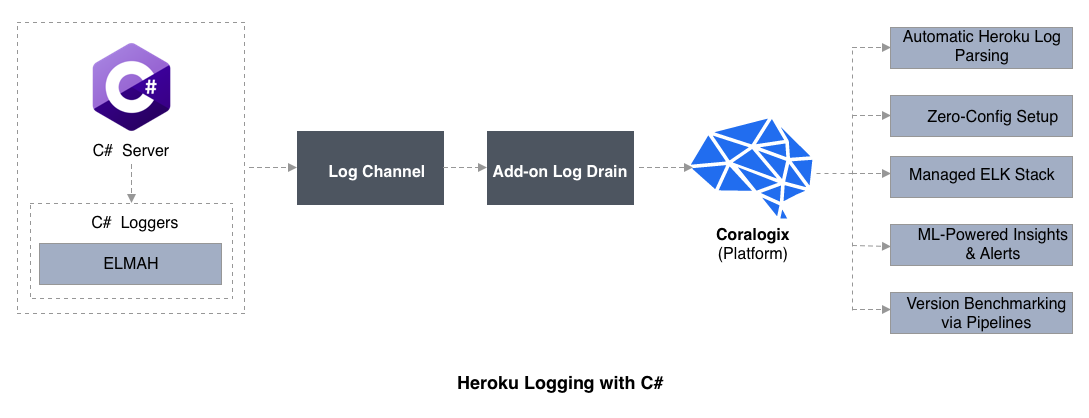
NLog and its API are easy to set up as illustrated in the example below. Reviews merits information technology's faster than log4net. Nlog handles structured logging of most popular databases. Nosotros tin can extend NLog to write logs to any destination. Here is an example to set up Nlog to send logging output to Heroku. First, configure an XML file in lawmaking like this:
var config1 = new NLog.Config.LoggingConfiguration(); var logfile1 = new NLog.Targets.FileTarget("logfile1") { FileName = "file1.txt" }; var logconsole1 = new NLog.Targets.ConsoleTarget("logconsole"); config1.AddRule(LogLevel.Info, LogLevel.Fatal, logconsole); config1.AddRule(LogLevel.Debug, LogLevel.Fatal, logfile1); NLog.LogManager.Configuration = config1; At present, add a class with a method to write to the log:
class MyClass { private static readonly NLog.Logger _log_ = NLog.LogManager.GetCurrentClassLogger(); public void Foo() { _log.Debug("Logging started"); _log.Info("How-do-you-do {Name}", "Johnathan"); } } Logging Libraries for C#
Like Log4NET, which has always been the .Net logging standard, NLog supports multiple logging targets and logs messages to many types of information stores. Equally for standard logging practices, both nowadays similar features. ELMAH is a C# logging library that does offer several differences.
- ELMAH, which means "Mistake Logging Modules And Handlers," on the other manus, does offer features beyond the standard fare. ELMAH is an open up-source library that logs runtime errors in the product environment. A distinctive component of ELMAH, beyond error filtering, is its adequacy to display error logs on a web page in the class of RSS feeds. Here'due south a screenshot of ELMAH displaying an fault log as a web folio:
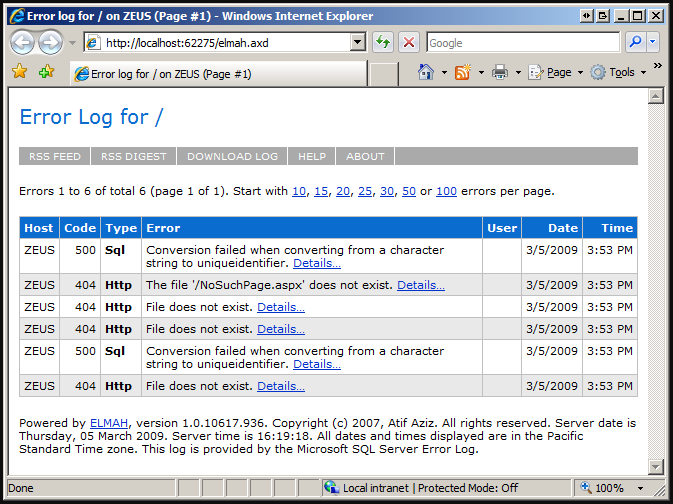
Prototype source
Hands-On Example: Troubleshooting Heroku
To illustrate the value and importance of Heroku logs, we will run a sample app and look at some commonly encountered issues. We volition starting time past deploying a simple Python app and watch how Heroku logs an issue when the app runs. Later we will calibration the app and introduce a more than subtle bug to find out how a vast log output ultimately calls for a solution to assist developers in the task of pinpointing bugs.
Note: Be sure you have created a free Heroku account, and your linguistic communication of choice is installed:
Step i: Install Heroku locally
Step 2: Install GIT to run the Heroku CLI
Step three: Utilize the Heroku CLI to login to Heroku
Step 4: Clone a GIT app locally to deploy to a Heroku Dyno
$ git clone https://github.com/heroku/python-getting-started.git $ cd python-getting-started
Step v: Create your app on Heroku, which:
- Creates a remote GIT via Heroku and
- Assembly it with your local GIT clone
- Deploy on Linux, for case with
$ git push heroku master
Footstep half-dozen: Open up the app in the browser with the Heroku CLI shortcut:
$ heroku open
At this bespeak, if y'all're following along with Heroku's case deployment, you can run across the Heroku log generated past deploying and opening the app. Let's look at the kickoff obvious app outcome:
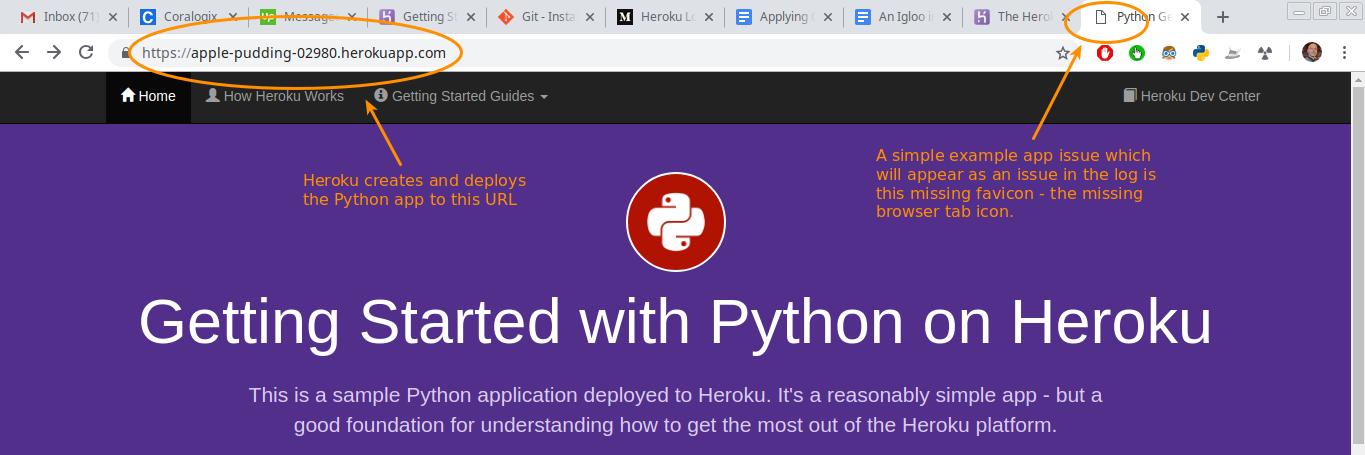
As you can meet, Heroku generated a name and URL for this deployment, and the browser tab icon (favicon) which is missing instantly appears in the log:
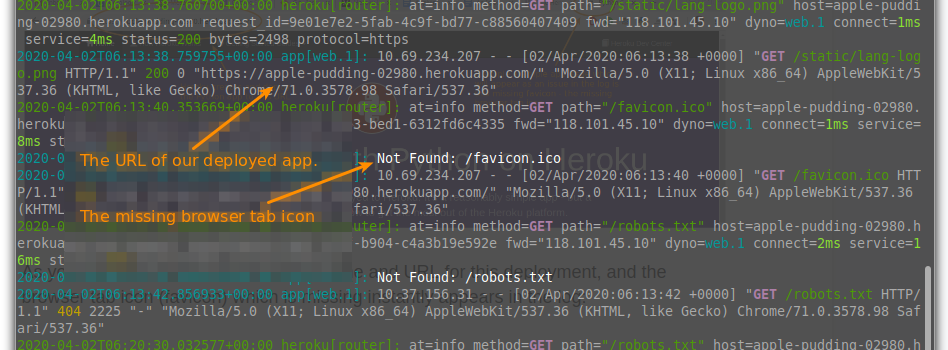
The volume of log output generated by deploying this simple Python app hints at the need for intelligent log monitoring and analytics. As nosotros calibration this simple app to reveal the more complex log output generated by Heroku during enterprise-level app development and deployment, the need for machine learning-capable analytics becomes imperative.
Avoiding a Common Issue with Heroku Logs
From this point on, developers can enter a natural CI/CD bicycle of revising code and committing the changes to deployment, configuring a Bleed with a logging app, and watching the dashboard for issues. However, for developers only starting out with Heroku, the adjacent steps to deploy the code change from the local GIT repo may present two surprising problems. Afterwards making a code change to the local GIT, Heroku documentation offers these CLI instructions which should find files that changed and deploy them to production, updating our app:
$ git add together $ git commit -k "Commencement code alter" $ git button heroku primary
The first trouble, when using the CLI command $ git commit is a GIT message asking who you are. This is function of a first-time hallmark setup:

Define your identity with the CLI commands suggested:
$ git config --global user.email "[e-mail protected]" $ git config --global user.name "marko"
Now, with that done, when deploying the app with $ git button heroku chief another potentially disruptive hallmark message occurs:
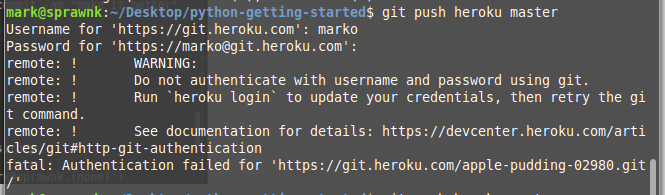
Notice that there is no mention of an API central in the dialog. As shown in a higher place, the "marko" id created previously is the correct username sought in this context. However, the "countersign" in this context is not the Heroku account countersign, merely instead, the Heroku API key found on this page (you demand to be signed in).
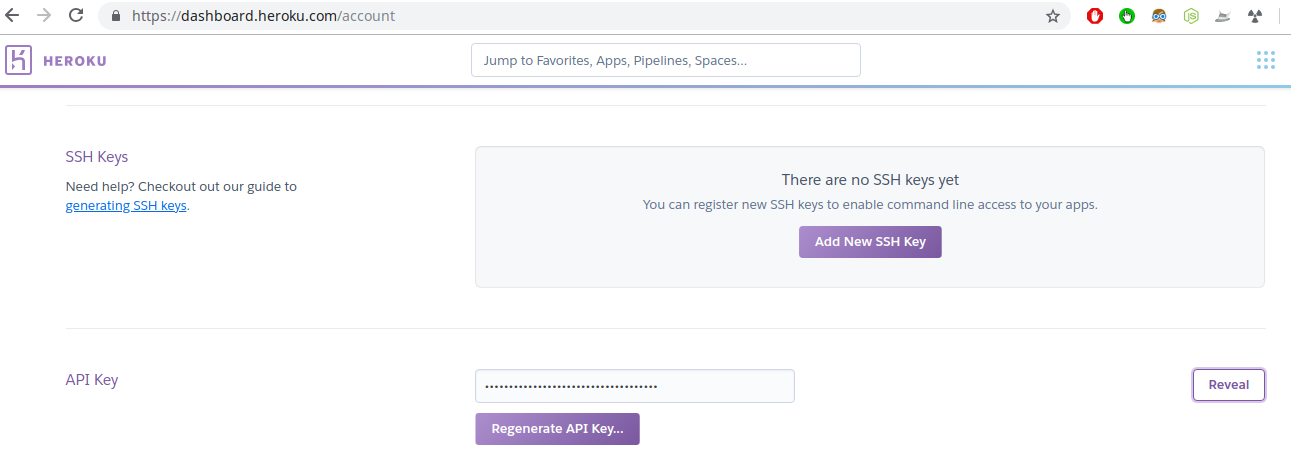
Equally shown in the next screenshot, the "password" is the API cardinal.
Scroll down the account folio and click the reveal button, and so copy and paste that key to the CLI in your concluding, depending on your setup:
At this indicate, with Heroku and GIT both authenticated correctly, the new changes tin exist deployed from the local GIT repo with this Heroku CLI command:
$ git push heroku main
From this point forward, code changes tin be made and committed to deployment easily and then that Heroku log streams menstruation from Logplex to designated endpoints. Now that we accept this workflow in place, it's a simple affair with the Heroku platform to make code changes and commit them to deployment from the CLI.
Finding Retention Leaks with Heroku Log Monitoring
I mutual frustration for coders tin can occur due to the fact that, in spite of automated garbage drove, retentiveness leaks can announced in logs from applications running in production which seem to have no obvious origin. Information technology can oftentimes be difficult for developers to find the cause in their code; it may seem logically correct, merely we oft need to look deeper for the cause. A few examples include:
- Loopback app in Node.js deployed to Heroku with a bleed to New Relic. Running the app locally does not show increased memory employ, but when the app is deployed to Heroku with New Relic, the heap steadily increases, even with no new requests.
- Subtle references to variables, such as closures. These nonetheless count as references to variables, and as a result, garbage collection will non release the retention. Diverse types of dependencies may besides not be obvious when examining app lawmaking, but can also consequence in memory leaks which show upwards when the app is deployed.
- Mysterious Gateway Timeout entries appear in the log, simply a memory leak was non detected in log analysis. For case, in a desperate effort to notice the trouble, a programmer is likely to wrap the lawmaking in Q-promises, examine heap sizes and MongoDB payloads, and explore many other avenues before discovering the retention leak in a data streaming method failure.
The common denominator in all these examples is that retention leak bugs may appear in your Heroku Logs and the developer may not recognize them in the app logic. These retentiveness leaks tin be extremely frustrating to troubleshoot and can lead coders to believe that the bug is actually in the V8 Heap, but more ofttimes, the issues lies in the app code itself.
Beginner Tip: Memory leaks occur when a program does not release unused memory. When undetected, memory leaks tend to accumulate and reduce app performance and tin even cause failure. The "garbage collection" function of many compilers, specially Rust, is capable of adding code to compiled apps that discard unused memory. For example, in C++ this tin can prevent attacks on discarded pointers.
Heroku Logs For Faster Troubleshooting
Every bit we've seen, Heroku Logplex generates voluminous log content that contains entries generated by every behavioral aspect of an application's deployment and runtime. Heroku logs are a vast resource for developers and members concerned with application operation and squashing bugs rapidly.
Yet, logging has evolved far beyond debugging software and is now i of many focal points for the utilise of car learning techniques to excerpt all the latent value in Heroku log data.
Software development in the context of enterprise CI/CD environments requires substantial automation to ensure loftier performance and reliable systems. Log management and assay are critical areas of automation in software development. While Heroku logs are a vast source of data, Heroku log analysis add together-ons similar Coralogix are needed to excerpt the full value of your log data goldmine.
Technologies that remove logging inefficiencies, reduce data storage cost, and propel problem-solving with automation and motorcar learning will play a decisive office in determining your organization'south ability to create business concern value faster.
Coralogix Addition for Heroku
If you're looking for a powerful yet easy-to-use Heroku logging solution, expect no farther than Coralogix. A managed, scaled and compliant ELK stack powered past proprietary ML-techniques.
Source: https://coralogix.com/blog/heroku-logs-the-complete-guide/
{kind=link}
Post a Comment for "Heroku Connection to Log Stream Failed. Please Try Again Later."